teaching the machine to hallucinate
June 17, 2015 10:55 PM Subscribe
Google Photos recognizes the content of images by training neural networks. Google Research is conducting experiments on these simulated visual brains by evolving images to hyperstimulate them, creating machine hallucinations - like that image of melting squirrels that's been going around lately.
{kind=link}
A consensual hallucination experienced daily by billions of legitimate operators, in every nation, by children being taught mathematical concepts.
posted by a lungful of dragon at 11:01 PM on June 17, 2015 [6 favorites]
posted by a lungful of dragon at 11:01 PM on June 17, 2015 [6 favorites]
I don't see any electric sheep.
posted by Johnny Wallflower at 11:03 PM on June 17, 2015 [2 favorites]
posted by Johnny Wallflower at 11:03 PM on June 17, 2015 [2 favorites]
This seems like it ought to have been a story by Phillip K. Dick. Did he write a story with this plot?
The images seem like if Van Gogh had gotten to a surrealist phase.
posted by LeRoienJaune at 11:04 PM on June 17, 2015 [1 favorite]
The images seem like if Van Gogh had gotten to a surrealist phase.
posted by LeRoienJaune at 11:04 PM on June 17, 2015 [1 favorite]
This is pretty impressive. If I follow it correctly, they ask the neural network to find and enhance things that it had already been given examples of. Sometimes they told it what to look for and sometimes they didn't. The pattern matching goes wild without a check to say "this match is very unlikely". I think "hallucination" is a very apt term for this experiment.
posted by demiurge at 11:06 PM on June 17, 2015 [5 favorites]
posted by demiurge at 11:06 PM on June 17, 2015 [5 favorites]
I saw that melting squirrel photo a few days ago on Facebook with a caption saying it had been generated by a neural network, but its fidelity to the visual experience of taking mushrooms made me think that the attribution couldn't possibly be correct. So needless to say my reaction to seeing it again here was basically this.
posted by invitapriore at 11:11 PM on June 17, 2015 [4 favorites]
posted by invitapriore at 11:11 PM on June 17, 2015 [4 favorites]
wow, for some reason this really takes my breath away. it's, like, sublime and terrifying and beautiful and weirdly spiritual. maybe I need sleep.
posted by threeants at 11:12 PM on June 17, 2015 [7 favorites]
posted by threeants at 11:12 PM on June 17, 2015 [7 favorites]
Some of these pieces are museum-worthy, holy fuck they're beautiful, zoom in real close for details, it's insane, a computer made that, we straight up live in the future.
[Smoke weed every daaaay]
posted by jake at 11:12 PM on June 17, 2015 [20 favorites]
[Smoke weed every daaaay]
posted by jake at 11:12 PM on June 17, 2015 [20 favorites]
I don't know, something about the whole "the computer created these crazy, beautiful worlds out of random noise" thing both resonated with me and totally chilled me because, like...isn't that also sort of exactly what the universe actually just is?
posted by threeants at 11:14 PM on June 17, 2015 [6 favorites]
posted by threeants at 11:14 PM on June 17, 2015 [6 favorites]
OH GOD YOU'RE KILLING ME RIGHT NOW
posted by jake at 11:16 PM on June 17, 2015 [5 favorites]
posted by jake at 11:16 PM on June 17, 2015 [5 favorites]
Fascinating. My research group uses machine learning of language features to predict psychological and demographic outcomes like extroversion and gender. We don't use deep networks, but if we did, we could generate language (following syntax rules like they do with pixel autocorrelation) that's typical of extroverts or men, or at least highly likely to be classified as such. (NB: the "men" one would be all profanity and Call of Duty. Language features aren't as abstract as image pixels.) They're turning a discriminative NN classifier into a generative model, in a way. Neat.
posted by supercres at 11:17 PM on June 17, 2015 [10 favorites]
posted by supercres at 11:17 PM on June 17, 2015 [10 favorites]
It's a bit dry, but for those interested in learning more about this sort of thing the Backpropagation article on Wikipedia would be a decent starting point.
posted by Ryvar at 11:20 PM on June 17, 2015 [1 favorite]
posted by Ryvar at 11:20 PM on June 17, 2015 [1 favorite]
Holy crap. These are amazing, and produced purely from noise.
posted by erratic meatsack at 11:21 PM on June 17, 2015 [2 favorites]
{kind=link}
posted by erratic meatsack at 11:21 PM on June 17, 2015 [2 favorites]
Oh great. Machines are taking MY job now, too.
posted by louche mustachio at 11:32 PM on June 17, 2015 [8 favorites]
posted by louche mustachio at 11:32 PM on June 17, 2015 [8 favorites]
any bona fide Art Critics care to weight in on these?
posted by dilaudid at 11:35 PM on June 17, 2015
posted by dilaudid at 11:35 PM on June 17, 2015
In a few years, when brain scanners are more precise, they'll be able to do the same thing to us. You'll look at a screen of random static while the scanner monitors the dog-sensitive neurons in your head, and slowly the static will fade into the most doggiest dog you've ever seen.
posted by moonmilk at 11:39 PM on June 17, 2015 [2 favorites]
posted by moonmilk at 11:39 PM on June 17, 2015 [2 favorites]
Yeah. This is amazing stuff. One of those classic "obvious as soon as you see it" things, for me anyway. Do a Google image search for "impressionist art". This technique seems to pretty much define it.
posted by merlynkline at 11:56 PM on June 17, 2015 [1 favorite]
posted by merlynkline at 11:56 PM on June 17, 2015 [1 favorite]
Oh great. Machines are taking MY job now, too
Your job is to trip?
posted by univac at 12:00 AM on June 18, 2015 [4 favorites]
Your job is to trip?
posted by univac at 12:00 AM on June 18, 2015 [4 favorites]
We don't use deep networks, but if we did, we could generate language (following syntax rules like they do with pixel autocorrelation) that's typical of extroverts or men, or at least highly likely to be classified as such.
I would love to see the results of such a project. It might be feasible as a side project for myself or whoever else is motivated; there exist toolkits for deep learning like PDNN. (Properly training one might require more computing resources than one person generally has access to, though.)
Has your research group published anything available on, say, arXiv or Google Scholar?
posted by Rangi at 12:04 AM on June 18, 2015
I would love to see the results of such a project. It might be feasible as a side project for myself or whoever else is motivated; there exist toolkits for deep learning like PDNN. (Properly training one might require more computing resources than one person generally has access to, though.)
Has your research group published anything available on, say, arXiv or Google Scholar?
posted by Rangi at 12:04 AM on June 18, 2015
Yeah, the machine hallucinations' uncanny resemblance to people hallucinations (well, as I understand them) is, like, kind of scaring me right now.
posted by univac at 12:06 AM on June 18, 2015 [4 favorites]
posted by univac at 12:06 AM on June 18, 2015 [4 favorites]
Some of these pieces are museum-worthy, holy fuck they're beautiful, zoom in real close for details, it's insane, a computer made that, we straight up live in the future.
I thought the same thing about some of them - for example the interpretation of the antelopes. I don't think I've seen computer generated media where the "first attempt" at a particular approach was so striking.
We have come to regard (computer algorithm processed) digital photography as providing a yardstick for realistic depiction of what is out there. What we see with our own eyes is less trustworthy. What we see when we look at Bosch or Van Gogh is the essence of that untrustworthiness further amplified by artists who were both gifted and mentally unstable. To be able to replicate that creative distortion of reality with a machine algorithm is pretty amazing.
posted by rongorongo at 12:08 AM on June 18, 2015 [2 favorites]
I thought the same thing about some of them - for example the interpretation of the antelopes. I don't think I've seen computer generated media where the "first attempt" at a particular approach was so striking.
We have come to regard (computer algorithm processed) digital photography as providing a yardstick for realistic depiction of what is out there. What we see with our own eyes is less trustworthy. What we see when we look at Bosch or Van Gogh is the essence of that untrustworthiness further amplified by artists who were both gifted and mentally unstable. To be able to replicate that creative distortion of reality with a machine algorithm is pretty amazing.
posted by rongorongo at 12:08 AM on June 18, 2015 [2 favorites]
I wonder if this will give us any insight into our own visual processing as time goes on?
posted by Harald74 at 12:10 AM on June 18, 2015 [1 favorite]
posted by Harald74 at 12:10 AM on June 18, 2015 [1 favorite]
Is this literally the stuff nightmares are made of?
posted by merlynkline at 12:29 AM on June 18, 2015 [2 favorites]
posted by merlynkline at 12:29 AM on June 18, 2015 [2 favorites]
The AI Winter is over, maaaaan!
posted by rum-soaked space hobo at 2:18 AM on June 18, 2015 [3 favorites]
posted by rum-soaked space hobo at 2:18 AM on June 18, 2015 [3 favorites]
I really find this one beautiful
not so hallucinatory but just wonderful.
posted by quazichimp at 2:52 AM on June 18, 2015 [3 favorites]
not so hallucinatory but just wonderful.
posted by quazichimp at 2:52 AM on June 18, 2015 [3 favorites]
Looked at two, looked around the room to make sure i wasn't frying balls, then opened this and kept scrolling.
posted by emptythought at 3:43 AM on June 18, 2015 [1 favorite]
posted by emptythought at 3:43 AM on June 18, 2015 [1 favorite]
I really like the Ibises; many of the others are too grotesque to be pleasant for me, but that one I can just stare at. It seems to distill what's beautiful and graceful in those acacias.
posted by Wolfdog at 3:47 AM on June 18, 2015
{kind=link}
posted by Wolfdog at 3:47 AM on June 18, 2015
The ones with eyes are quite unsettling.
posted by RobotVoodooPower at 4:27 AM on June 18, 2015 [1 favorite]
posted by RobotVoodooPower at 4:27 AM on June 18, 2015 [1 favorite]
If this isn't a version of Dalí's paranoiac-critical method, well, I'm no burning giraffe …
posted by scruss at 4:27 AM on June 18, 2015 [2 favorites]
posted by scruss at 4:27 AM on June 18, 2015 [2 favorites]
Doesn't the use of the term "hallucination" for this imply a bunch of pretty major assumptions about the nature of hallucinations as experienced in living brains?
posted by lodurr at 4:38 AM on June 18, 2015
posted by lodurr at 4:38 AM on June 18, 2015
I think the major assumption is that you'll recognize an analogy when you see one.
posted by Wolfdog at 4:39 AM on June 18, 2015 [10 favorites]
posted by Wolfdog at 4:39 AM on June 18, 2015 [10 favorites]
I would purchase a poster of Sky Bright, but will make do with it as my desktop for now.
posted by robocop is bleeding at 4:47 AM on June 18, 2015 [1 favorite]
posted by robocop is bleeding at 4:47 AM on June 18, 2015 [1 favorite]
The ones with eyes are quite unsettling.
It does make you think our future AI overlords are going to be just as terrified as they are terrifying.
posted by mittens at 4:57 AM on June 18, 2015
It does make you think our future AI overlords are going to be just as terrified as they are terrifying.
posted by mittens at 4:57 AM on June 18, 2015
I would love to see the results of such a project.
I'm sure I've seen something about someone training a neural network to generate text recently... it seemed the results weren't any more interesting than a markov model trained on the same corpus, to me.
Yeah, here it is. Dig here.
posted by Leon at 4:58 AM on June 18, 2015 [2 favorites]
I'm sure I've seen something about someone training a neural network to generate text recently... it seemed the results weren't any more interesting than a markov model trained on the same corpus, to me.
Yeah, here it is. Dig here.
posted by Leon at 4:58 AM on June 18, 2015 [2 favorites]
The last time I was offered acid, it was at a Google event (*).
Yes, this stuff is deeply unsettling at a visceral level. Whether it's as unsettling to those who've never had a classic drug-induced psychedelic experience is a question. Those ibexes may look pretty if you haven't - they are pretty - but if you associate those visual effects with the call-them-what-you-like-but-they-sure-ain't-pretty other cognitive effects that come with LSD/psilocybin, then your reaction is going to be more, shall we say, nuanced.
And the melting squirrels. Mmm. Hello again, boys. It's been a while.
Now, we know quite a lot about the human visual system processing chain by now, and a lot of computer vision engineering is informed by that. We also have some headway (ho) into what happens when you hallucinate, at least in creating theoretical models and finding signs of underlying mechanisms. We know less about how the back end of the visual system interfaces with higher order cognition, but these images are clearly pretty good at triggering elements of that interface that are also triggered by whatever it is that's going on there when we are, as the current lingo has it, trippin' balls.
Would love to see brain activity scans of people looking at these, compared to people enjoying the odd indole group.
(*) Not, I should add, by anyone connected with Google. And they didn't come through. Frikkin' hippies.
posted by Devonian at 5:00 AM on June 18, 2015 [7 favorites]
Yes, this stuff is deeply unsettling at a visceral level. Whether it's as unsettling to those who've never had a classic drug-induced psychedelic experience is a question. Those ibexes may look pretty if you haven't - they are pretty - but if you associate those visual effects with the call-them-what-you-like-but-they-sure-ain't-pretty other cognitive effects that come with LSD/psilocybin, then your reaction is going to be more, shall we say, nuanced.
And the melting squirrels. Mmm. Hello again, boys. It's been a while.
Now, we know quite a lot about the human visual system processing chain by now, and a lot of computer vision engineering is informed by that. We also have some headway (ho) into what happens when you hallucinate, at least in creating theoretical models and finding signs of underlying mechanisms. We know less about how the back end of the visual system interfaces with higher order cognition, but these images are clearly pretty good at triggering elements of that interface that are also triggered by whatever it is that's going on there when we are, as the current lingo has it, trippin' balls.
Would love to see brain activity scans of people looking at these, compared to people enjoying the odd indole group.
(*) Not, I should add, by anyone connected with Google. And they didn't come through. Frikkin' hippies.
posted by Devonian at 5:00 AM on June 18, 2015 [7 favorites]
The sky one is kind of sweet if you choose to think the computer is looking for shapes in the clouds instead of tripping balls.
posted by mccarty.tim at 5:20 AM on June 18, 2015
posted by mccarty.tim at 5:20 AM on June 18, 2015
This is super cool. It's really interesting to me how many of the higher order features seem to resemble (animal or human) faces. I guess this is due too how much of the training set includes faces. That seems very human to me, like how people are constantly finding faces in inanimate objects.
For what it's worth, my favourites are the ones with masses of towers and archways. And also the pine trees = pagodas ones. And this fantasy landscape.
posted by quaking fajita at 5:22 AM on June 18, 2015 [3 favorites]
For what it's worth, my favourites are the ones with masses of towers and archways. And also the pine trees = pagodas ones. And this fantasy landscape.
posted by quaking fajita at 5:22 AM on June 18, 2015 [3 favorites]
We ask the network: “Whatever you see there, I want more of it!” This creates a feedback loop: if a cloud looks a little bit like a bird, the network will make it look more like a bird. This in turn will make the network recognize the bird even more strongly on the next pass and so forth, until a highly detailed bird appears, seemingly out of nowhere.Does anyone know whether there are videos / gifs of the interations anywhere? Watching the images grow out of the static would be fascinating.
posted by metaBugs at 5:31 AM on June 18, 2015 [3 favorites]
(shiver) Nope Nope Nope Nope Nope
Not for the neural network stuff -- that's cool research. I just don't want to look at those images ever again.
posted by Mogur at 5:33 AM on June 18, 2015 [1 favorite]
Not for the neural network stuff -- that's cool research. I just don't want to look at those images ever again.
posted by Mogur at 5:33 AM on June 18, 2015 [1 favorite]
In a few years, when brain scanners are more precise, they'll be able to do the same thing to us. You'll look at a screen of random static while the scanner monitors the dog-sensitive neurons in your head, and slowly the static will fade into the most doggiest dog you've ever seen.
It's slower and more crude because there's no scanners involved, but people are kind of dipping toes into that already.
posted by traveler_ at 5:53 AM on June 18, 2015 [1 favorite]
It's slower and more crude because there's no scanners involved, but people are kind of dipping toes into that already.
posted by traveler_ at 5:53 AM on June 18, 2015 [1 favorite]
What I keep coming back to is that these are artifacts of the instrument's functioning. So, not the product of higher-level cognition -- which is to say, if this process does map to human hallucinations, then it probably also maps to hallucinations in "lower" animals.
...checks another item off the 'human excceptionalism' list....
posted by lodurr at 6:09 AM on June 18, 2015 [1 favorite]
...checks another item off the 'human excceptionalism' list....
posted by lodurr at 6:09 AM on June 18, 2015 [1 favorite]
Welp, this has reinforced my wanting to stay the hell away from hallucinogens.
posted by Mr. Bad Example at 6:14 AM on June 18, 2015
posted by Mr. Bad Example at 6:14 AM on June 18, 2015
"Now, we know quite a lot about the human visual system processing chain by now, and a lot of computer vision engineering is informed by that. We also have some headway (ho) into what happens when you hallucinate, at least in creating theoretical models and finding signs of underlying mechanisms. We know less about how the back end of the visual system interfaces with higher order cognition, but these images are clearly pretty good at triggering elements of that interface that are also triggered by whatever it is that's going on there when we are, as the current lingo has it, trippin' balls."
I think it's important to distinguish between what you're calling the "back end" stuff and the stuff that seems very hallucinogenic. You can't fully distinguish them, of course. But the the designed structure of the neural net is very much like the human visual system processing chain, as you put it, and the recursive excitement of discrete layers of that chain (which is a researchers' deliberate, targeted manipulation) ends up distorting the output of that layer of the chain and therefore the whole of it that unsurprisingly mimic how certain drugs similarly distorting human visual cognitive processing. So we get results of edge and color distortions, or of continuity distortions, that end up being very much like what we experience on these drugs. Because these are, by design, very similar systems.
And that's really cool because it's demonstrating that these systems really are functioning similarly.
Now, with the "back end" stuff, the, shall we say, "semantically" loaded transformations that's not much like human cognition at all, really, and it's not much like how hallucinogens will elicit symbolically-loaded visual imagery (or associations with visual imagery). The results we're seeing in these photos may seem like that, but that's a product of how the system as whole -- by which I mean the choices made in both designing and training the neural net and some other things -- is inherently and necessarily a product of a selective and narrow slice of human symbolic cognition. In the same way that our camera takes photos and our scrapbooks (or phones) are filled with photos of meaningful objects, it's not that the camera understands meaningful objects or that the scrapbooks or the phones do, it's that we do when we choose the things we take photos of. We could have taken photos of unidentifiable and meaningless things, say.
So, sure, in some sense the meaning has been encoded into the neural nets because, yeah, there's some visual sense of dogs and buildings and eyes buried in the neural net. But those things being elicited by this process aren't really similar to those things being elicited in our brains by hallucinogens, because while it's probably true that there's a few latent shapes and such in those remote visual processing areas of the brain, a whole lot of the stuff elicited by drugs in our brains comes from the deep memory and semantically meaningful parts of our cognition and these neural nets don't have anything like that at all. They're producing dogs and buildings and eyes because they've been trained on dogs and buildings and eyes and not the billion or so other things that they might have been trained on.
What's really interesting is in how those predictable objects (predictable because the nets were trained on them) end up being integrated into the more fundamental bits of the images. And, again, that relationship may be one thing about these larger structures that is similar to what happens in our brains -- there's an interplay between the lower-level stuff and how the higher-level elicited stuff fits into it, and these nets might give us a bit of insight into how that works.
posted by Ivan Fyodorovich at 6:31 AM on June 18, 2015 [4 favorites]
I think it's important to distinguish between what you're calling the "back end" stuff and the stuff that seems very hallucinogenic. You can't fully distinguish them, of course. But the the designed structure of the neural net is very much like the human visual system processing chain, as you put it, and the recursive excitement of discrete layers of that chain (which is a researchers' deliberate, targeted manipulation) ends up distorting the output of that layer of the chain and therefore the whole of it that unsurprisingly mimic how certain drugs similarly distorting human visual cognitive processing. So we get results of edge and color distortions, or of continuity distortions, that end up being very much like what we experience on these drugs. Because these are, by design, very similar systems.
And that's really cool because it's demonstrating that these systems really are functioning similarly.
Now, with the "back end" stuff, the, shall we say, "semantically" loaded transformations that's not much like human cognition at all, really, and it's not much like how hallucinogens will elicit symbolically-loaded visual imagery (or associations with visual imagery). The results we're seeing in these photos may seem like that, but that's a product of how the system as whole -- by which I mean the choices made in both designing and training the neural net and some other things -- is inherently and necessarily a product of a selective and narrow slice of human symbolic cognition. In the same way that our camera takes photos and our scrapbooks (or phones) are filled with photos of meaningful objects, it's not that the camera understands meaningful objects or that the scrapbooks or the phones do, it's that we do when we choose the things we take photos of. We could have taken photos of unidentifiable and meaningless things, say.
So, sure, in some sense the meaning has been encoded into the neural nets because, yeah, there's some visual sense of dogs and buildings and eyes buried in the neural net. But those things being elicited by this process aren't really similar to those things being elicited in our brains by hallucinogens, because while it's probably true that there's a few latent shapes and such in those remote visual processing areas of the brain, a whole lot of the stuff elicited by drugs in our brains comes from the deep memory and semantically meaningful parts of our cognition and these neural nets don't have anything like that at all. They're producing dogs and buildings and eyes because they've been trained on dogs and buildings and eyes and not the billion or so other things that they might have been trained on.
What's really interesting is in how those predictable objects (predictable because the nets were trained on them) end up being integrated into the more fundamental bits of the images. And, again, that relationship may be one thing about these larger structures that is similar to what happens in our brains -- there's an interplay between the lower-level stuff and how the higher-level elicited stuff fits into it, and these nets might give us a bit of insight into how that works.
posted by Ivan Fyodorovich at 6:31 AM on June 18, 2015 [4 favorites]
I'm sure I've seen something about someone training a neural network to generate text recently
Most recently on metafilter: YOWL THE COOKIE (with a list of various recent applications of the Karpathy code in this comment).
When I first saw the melting, multi-eyed ferrets image it reminded me (with a lot of slippage) of a 2D visual analog of n-grams or RNN-generated text.
posted by jjwiseman at 6:48 AM on June 18, 2015
Most recently on metafilter: YOWL THE COOKIE (with a list of various recent applications of the Karpathy code in this comment).
When I first saw the melting, multi-eyed ferrets image it reminded me (with a lot of slippage) of a 2D visual analog of n-grams or RNN-generated text.
posted by jjwiseman at 6:48 AM on June 18, 2015
I wonder if this can be applied to software. Give it a folderfull of Atari 2600 ROMs (which are basically video hallucinations anyway)
posted by RobotVoodooPower at 7:18 AM on June 18, 2015
posted by RobotVoodooPower at 7:18 AM on June 18, 2015
"I wonder if this can be applied to software. Give it a folderfull of Atari 2600 ROMs (which are basically video hallucinations anyway)"
This isn't what you had in mind, but here's a video I watched just the other day of a neural net playing Super Mario World, with a lot of explanation by the programmer.
posted by Ivan Fyodorovich at 7:23 AM on June 18, 2015 [3 favorites]
This isn't what you had in mind, but here's a video I watched just the other day of a neural net playing Super Mario World, with a lot of explanation by the programmer.
posted by Ivan Fyodorovich at 7:23 AM on June 18, 2015 [3 favorites]
I’m not sure that agree Ivan (well, I think I know what I think, but I’m not sure if you think it too!): The brain is a trained neural net (albeit a far more complex one), so isn’t the difference here one of scale. The brain seems to work by pattern matching, and that’s exactly the behaviour that this algorithm is exhibiting by finding familiar structures apophenically. Human brains have far greater pattern matching capabilities, to the extent that they are able to recognise themselves as a pattern. They also seem to have a more modular structure - the primary visual area sends signals to the visual association area, which sends signals to the common integrative area etc. Each of these areas relates its input to previous inputs and to inputs from other sensory areas, allowing us to build up a cohesive picture. As the neural net in the article only simulates the first couple of steps of this process, I don’t think it’s fair to penalise it for failing to carry out functions that are normally carried put further down the perceptual/conceptual chain.
You say that the neural net only produces dogs and buildings because that’s all it’s been trained on, but how’s that any different from human hallucination? People don’t create the concept of a pink or elephant or whatever when they take LSD, it’s the product of previous sensory experiences. Human brains happen to have the advantage of this conceptual and linguistic framework with which they can interpret their sensory inputs, but I don’t think that makes a big difference.
In the previous couple of paragraphs I’ve been assuming that interpretations follow a unidirectional chain, which is probably false (especially when talking about drug induced hallucination), where I imagine that there is interplay between higher level functions, such as emotion, and sensory interpretation going on. However, I don’t think that that makes a difference, as those higher level functions are also neural nets, which have been trained on previous inputs. It’s recursive neural networks all the way down.
posted by Ned G at 7:26 AM on June 18, 2015 [3 favorites]
You say that the neural net only produces dogs and buildings because that’s all it’s been trained on, but how’s that any different from human hallucination? People don’t create the concept of a pink or elephant or whatever when they take LSD, it’s the product of previous sensory experiences. Human brains happen to have the advantage of this conceptual and linguistic framework with which they can interpret their sensory inputs, but I don’t think that makes a big difference.
In the previous couple of paragraphs I’ve been assuming that interpretations follow a unidirectional chain, which is probably false (especially when talking about drug induced hallucination), where I imagine that there is interplay between higher level functions, such as emotion, and sensory interpretation going on. However, I don’t think that that makes a difference, as those higher level functions are also neural nets, which have been trained on previous inputs. It’s recursive neural networks all the way down.
posted by Ned G at 7:26 AM on June 18, 2015 [3 favorites]
Maybe a simpler way of thinking about it is if we split the brain into a two part chain: [basic visual processing] -> [everything else]. The network in the article is only attempting to simulate part one of that chain, and I think that we can’t criticise it for not doing things in the domain of part 2. We can however provide part 2 of the chain ourselves: I don’t believe that actually is a picture of a ‘melting squirrel’ without a person being present to interpret it as such. So then we have a chain [computer basic visual processing (hallucination mode)] -> [human basic visual processing] -> [everything else]. And this is approximately equivalent to [human basic visual processing (hallucination mode)] -> [everything else], which implies visual meaning has been encoded in the images in the same way; it’s just interpretation that’s missing.
The process obviously lacks dynamism because there’s no information going from [everything else] -> [basic visual processing], but I don’t think that makes a difference.
posted by Ned G at 7:40 AM on June 18, 2015 [2 favorites]
The process obviously lacks dynamism because there’s no information going from [everything else] -> [basic visual processing], but I don’t think that makes a difference.
posted by Ned G at 7:40 AM on June 18, 2015 [2 favorites]
Gifs exist, but I don't think they've been released yet. (and they're amaze-balls.) :)
posted by kaibutsu at 7:54 AM on June 18, 2015 [6 favorites]
posted by kaibutsu at 7:54 AM on June 18, 2015 [6 favorites]
"You say that the neural net only produces dogs and buildings because that’s all it’s been trained on, but how’s that any different from human hallucination? People don’t create the concept of a pink or elephant or whatever when they take LSD, it’s the product of previous sensory experiences. Human brains happen to have the advantage of this conceptual and linguistic framework with which they can interpret their sensory inputs, but I don’t think that makes a big difference."
I agree with this, but my point was that the semantically-meaningful parts of visual hallucinations in human brains occurs within a context where those symbols exist within the neural net as the symbols and not merely as a lower-level artifact of the visual processing the way that shape boundaries and color constancy and edge continuity and the like all do.
I fully subscribe to the mechanistic view of human cognition and so I surely do agree that it's neural nets all the way down. I'm not disputing that. But the lower-level stuff that the nets are doing when they're manipulated in these ways is genuinely moderately similar to what the human visual processing is doing when it's altered by drugs that affect those parts of our visual cognition. However, the higher-level stuff that the nets are doing -- seeing dogs and buildings -- isn't really similar to what the human brain is doing when it's altered by drugs because those dogs and buildings are things that each of the respective neural nets have been specifically trained to recognize while, in contrast, those sorts of symbolically-meaningful imagery in human hallucinations are elicited at least partly from the parts of the brain that aren't the visual system.
posted by Ivan Fyodorovich at 7:58 AM on June 18, 2015 [1 favorite]
I agree with this, but my point was that the semantically-meaningful parts of visual hallucinations in human brains occurs within a context where those symbols exist within the neural net as the symbols and not merely as a lower-level artifact of the visual processing the way that shape boundaries and color constancy and edge continuity and the like all do.
I fully subscribe to the mechanistic view of human cognition and so I surely do agree that it's neural nets all the way down. I'm not disputing that. But the lower-level stuff that the nets are doing when they're manipulated in these ways is genuinely moderately similar to what the human visual processing is doing when it's altered by drugs that affect those parts of our visual cognition. However, the higher-level stuff that the nets are doing -- seeing dogs and buildings -- isn't really similar to what the human brain is doing when it's altered by drugs because those dogs and buildings are things that each of the respective neural nets have been specifically trained to recognize while, in contrast, those sorts of symbolically-meaningful imagery in human hallucinations are elicited at least partly from the parts of the brain that aren't the visual system.
posted by Ivan Fyodorovich at 7:58 AM on June 18, 2015 [1 favorite]
They kind of gloss over the image generation part in this blog post - they just say
We ask the network: “Whatever you see there, I want more of it!”But the network is only for image recognition, not image production - the system that makes new images for the network to see is covered more in the papers they reference:
see related work in [1], [2], [3], [4]posted by moonmilk at 8:04 AM on June 18, 2015 [7 favorites]
A.I. "This is a picture of a dog. I will put a dog in here, but with a body of a snail."
Engineer: "That was a tree, AI."
posted by surazal at 8:49 AM on June 18, 2015
Engineer: "That was a tree, AI."
posted by surazal at 8:49 AM on June 18, 2015
I think what Ivan's getting at is that these recognizers have no sense of context. Humans know enough about knights and horses to know you're not going to find a Rottweiler inside either, even if a saddle is shaped more or less like the snout. Humans recognize images from context as much as, I guess, "content" like edges and textures.
posted by LogicalDash at 10:06 AM on June 18, 2015
posted by LogicalDash at 10:06 AM on June 18, 2015
Speaking of context, I wonder if a "smarter" version of this could make something closer to the "ENHANCE" effect you see in movies.
While it's common sense you can't just magically add pixels the camera didn't capture, you can recognize things in a low-resolution picture. Pixel artists strive to get your eyes to recognize as much as possible from a tiny space. For example, jagged artifacts could be smoothed out when the computer knows what the curve or line would be like in that spot if it recognizes the object. It'd be like anti-aliasing after the fact.
posted by mccarty.tim at 10:34 AM on June 18, 2015 [1 favorite]
While it's common sense you can't just magically add pixels the camera didn't capture, you can recognize things in a low-resolution picture. Pixel artists strive to get your eyes to recognize as much as possible from a tiny space. For example, jagged artifacts could be smoothed out when the computer knows what the curve or line would be like in that spot if it recognizes the object. It'd be like anti-aliasing after the fact.
posted by mccarty.tim at 10:34 AM on June 18, 2015 [1 favorite]
I shudder to think what prosecution teams would will do with that.
posted by lodurr at 10:41 AM on June 18, 2015 [1 favorite]
posted by lodurr at 10:41 AM on June 18, 2015 [1 favorite]
mccarty.tim, this research from 2001 does just that, for faces.
posted by moonmilk at 10:43 AM on June 18, 2015 [2 favorites]
posted by moonmilk at 10:43 AM on June 18, 2015 [2 favorites]
I'm not sure, but this one loo͘ks ͢a bit like hi̡s͞ ̵e͞a̧r̀th̢ly ͝me͏s͞se̕ng̀e̛r̛
o̢̞͍̺h̖̫͢ ̘̦͉̤̹g̘o͍̤͠d̰̜̺̗͚̤̮ w̹̝̟̳h͕̳͖y̫̪̲͇̟̲ ͈̳͇̦̘͇̹ar̰̬͕̝̤̻ͅe̩͚͇̭͈̳ͅ ̳̘̦̙̮̳t͇̳̟͔͈̱h͈̠̰̳͈è̟͇̬̗ͅ ̘̯̯͎̦͈w͓̭̲͖̫̻a͎̟̺̪̟l͇͎͇͈̖l̗̤͖s ͞b͠e̳ͅg͚͙i͓̼̠̼̰̪n͎͕n̨̺͈̹̯i̞̜͈̮̙̪̜n̨͚̣g̸̬̯͈̼͇ ̻̟̺͙̰̹t̨̲̰̮o̻̱̺̤̲͞ ̵͔̼͕b̥̖͔̻̥͡l̟͇̺̟̭̟e̦̼̻ͅe̖̤͔ͅd̜̯̩̮
w̸͉̮̺̤͍͎̗̖̹͉h̫͔̜̳̺̩̭̻͔̩͈̞͉͖̺͚́͟á̞͔̙̮̻̹̩͉̕ͅͅt͏̢̢̺̺̱͘ͅ ̢̠̤̲̰͢͜͠h̷̢̡̲͔̼̺̜̫̗̬à̡͍̗͔͖̩̩̮̮̬̟̕v̕͜͏̸͇͚̪͖̮̘͇͙̰͘e̷͢͏̬͈͎̪͓̻̟̲̠̳͕̯̞̼̦̳̱ͅ ̬̰̹̮͘͞y̷̸̬̭̗̗͉̦̟͇̮̖̱̺̰͎̥͠ò͏͏̙͖̥͙̤͖̙̳͕̗̤͙͉̥̯̩͕͠ų̹͍̜̭̙̥̠͍͉̜͙̙̱̤̦̥̟̤́́́͘ ͇̤̥̞̬͚̙̯̣͘͘d̵͜͏҉̠̲͖͓̤̤̭ơ̶̢̬͎͚̫̮̙̼͇̤̫̯͈͓ͅn̶̘̹̠̺͕͉̙e̛̘̯͇̫̬̠̥̩̼̼̻͈̕ ͓͙̙̼͙̣̰̤͇̲̹͉̦͎͍͚͠͝G̵̸̠̤̳̀͘ǫ̵̺̬̪̬̼̘͓̜̱͉͔̞̀͠͝ǫ̼̩̠̙̦̫̙̘̺̕͟͝g̶̺̼̮͎̝͈̯̪͈̩̠̝͇̤̘͍͍̜͜l̵̝͍̗̞̤̲̗̯̕ͅe̶̡̮͎͎͓̘̙̤̕ͅ
posted by Existential Dread at 11:07 AM on June 18, 2015 [8 favorites]
o̢̞͍̺h̖̫͢ ̘̦͉̤̹g̘o͍̤͠d̰̜̺̗͚̤̮ w̹̝̟̳h͕̳͖y̫̪̲͇̟̲ ͈̳͇̦̘͇̹ar̰̬͕̝̤̻ͅe̩͚͇̭͈̳ͅ ̳̘̦̙̮̳t͇̳̟͔͈̱h͈̠̰̳͈è̟͇̬̗ͅ ̘̯̯͎̦͈w͓̭̲͖̫̻a͎̟̺̪̟l͇͎͇͈̖l̗̤͖s ͞b͠e̳ͅg͚͙i͓̼̠̼̰̪n͎͕n̨̺͈̹̯i̞̜͈̮̙̪̜n̨͚̣g̸̬̯͈̼͇ ̻̟̺͙̰̹t̨̲̰̮o̻̱̺̤̲͞ ̵͔̼͕b̥̖͔̻̥͡l̟͇̺̟̭̟e̦̼̻ͅe̖̤͔ͅd̜̯̩̮
w̸͉̮̺̤͍͎̗̖̹͉h̫͔̜̳̺̩̭̻͔̩͈̞͉͖̺͚́͟á̞͔̙̮̻̹̩͉̕ͅͅt͏̢̢̺̺̱͘ͅ ̢̠̤̲̰͢͜͠h̷̢̡̲͔̼̺̜̫̗̬à̡͍̗͔͖̩̩̮̮̬̟̕v̕͜͏̸͇͚̪͖̮̘͇͙̰͘e̷͢͏̬͈͎̪͓̻̟̲̠̳͕̯̞̼̦̳̱ͅ ̬̰̹̮͘͞y̷̸̬̭̗̗͉̦̟͇̮̖̱̺̰͎̥͠ò͏͏̙͖̥͙̤͖̙̳͕̗̤͙͉̥̯̩͕͠ų̹͍̜̭̙̥̠͍͉̜͙̙̱̤̦̥̟̤́́́͘ ͇̤̥̞̬͚̙̯̣͘͘d̵͜͏҉̠̲͖͓̤̤̭ơ̶̢̬͎͚̫̮̙̼͇̤̫̯͈͓ͅn̶̘̹̠̺͕͉̙e̛̘̯͇̫̬̠̥̩̼̼̻͈̕ ͓͙̙̼͙̣̰̤͇̲̹͉̦͎͍͚͠͝G̵̸̠̤̳̀͘ǫ̵̺̬̪̬̼̘͓̜̱͉͔̞̀͠͝ǫ̼̩̠̙̦̫̙̘̺̕͟͝g̶̺̼̮͎̝͈̯̪͈̩̠̝͇̤̘͍͍̜͜l̵̝͍̗̞̤̲̗̯̕ͅe̶̡̮͎͎͓̘̙̤̕ͅ
posted by Existential Dread at 11:07 AM on June 18, 2015 [8 favorites]
"I think what Ivan's getting at is that these recognizers have no sense of context."
Not exactly.
I'm having a hard time explaining. It might help to understand where my thought process began -- people talking about how these were very like their experiences with some hallucinogens.
So if you think about that, you might see why I wanted to distinguish between the lower-level artifacts that the nets are producing and the higher-level recognizable shapes they're producing. Because each of those shapes were trained into different neural nets in the aim of getting those individual neural nets to recognize those shapes. And those were different nets for different shapes. Those shapes are very directly the inevitable product of what the researchers were selecting them to do. The lower-level stuff that the nets are doing are -- as you can tell from the examples -- common across the different nets with regard to the layers of the net that they decided to provoke. The lowest is probably the edge-detecting layer, then there is the color layer, and so on. They trained the nets to do those things, too, but those were generalized, the abilities of the nets to do these things are baked into the underlying structure of the kind of neural net architecture that they're using -- and that architecture is modeled on the corresponding lower-level layers of human visual processing.
Comparing that to a human brain under the influence of some hallucinogens, what we will see is that the lower-level effects are very much like the effects we're seeing in these photographs. And, again, that's because these nets are themselves structured quite similarly to the corresponding portion of our visual processing. However, that's not nearly so true of the higher-level recognizable shapes. In my previous paragraph, you can already see how there's a difference, because while the lower-level stuff is pretty similar between the two, our brain's storage and recall of recognizable shapes like "dog" is very different. I agree that, ultimately, it's encoded in something like a computational neural net somewhere in the brain. But I don't think that these semantically-meaningful objects are encoded anywhere near the visual processing areas where the lower-level stuff is. In the computer neural nets, it's just a layer or so above the others. And that works because those neural nets aren't doing what our brains do -- with regard to "dogs" it's doing something much, much simpler and so something as rudimentary as these neural nets are able to accomplish it.
But when we hallucinate such things, we're mixing in a cyclic fashion deep cognition and memory stuff with the visual processing stuff. The end result can freakily look very much the same, but that's because, ultimately, under the influence our brains are coming up with "dog" and then our under-the-influence visual processing center "melts" that dog and we get the resulting experience whereas with these neural nets these researcher's brains are coming up with "dog" (when they train the net) and then the provoked net "melts" the dog and we get the resulting images. The end result is similar, but that's because the really hard part -- having the concept of "dog" to begin with and then training the neural nets with it -- is still being done by actual brains.
That's not to say that, eventually, we won't have far more complex neural nets that generate "hallucinogenic" images of melting dogs that are actually at those deeper levels quite like what our brains produce; however, these images aren't really that. But they are very similar otherwise.
posted by Ivan Fyodorovich at 11:19 AM on June 18, 2015 [2 favorites]
Not exactly.
I'm having a hard time explaining. It might help to understand where my thought process began -- people talking about how these were very like their experiences with some hallucinogens.
So if you think about that, you might see why I wanted to distinguish between the lower-level artifacts that the nets are producing and the higher-level recognizable shapes they're producing. Because each of those shapes were trained into different neural nets in the aim of getting those individual neural nets to recognize those shapes. And those were different nets for different shapes. Those shapes are very directly the inevitable product of what the researchers were selecting them to do. The lower-level stuff that the nets are doing are -- as you can tell from the examples -- common across the different nets with regard to the layers of the net that they decided to provoke. The lowest is probably the edge-detecting layer, then there is the color layer, and so on. They trained the nets to do those things, too, but those were generalized, the abilities of the nets to do these things are baked into the underlying structure of the kind of neural net architecture that they're using -- and that architecture is modeled on the corresponding lower-level layers of human visual processing.
Comparing that to a human brain under the influence of some hallucinogens, what we will see is that the lower-level effects are very much like the effects we're seeing in these photographs. And, again, that's because these nets are themselves structured quite similarly to the corresponding portion of our visual processing. However, that's not nearly so true of the higher-level recognizable shapes. In my previous paragraph, you can already see how there's a difference, because while the lower-level stuff is pretty similar between the two, our brain's storage and recall of recognizable shapes like "dog" is very different. I agree that, ultimately, it's encoded in something like a computational neural net somewhere in the brain. But I don't think that these semantically-meaningful objects are encoded anywhere near the visual processing areas where the lower-level stuff is. In the computer neural nets, it's just a layer or so above the others. And that works because those neural nets aren't doing what our brains do -- with regard to "dogs" it's doing something much, much simpler and so something as rudimentary as these neural nets are able to accomplish it.
But when we hallucinate such things, we're mixing in a cyclic fashion deep cognition and memory stuff with the visual processing stuff. The end result can freakily look very much the same, but that's because, ultimately, under the influence our brains are coming up with "dog" and then our under-the-influence visual processing center "melts" that dog and we get the resulting experience whereas with these neural nets these researcher's brains are coming up with "dog" (when they train the net) and then the provoked net "melts" the dog and we get the resulting images. The end result is similar, but that's because the really hard part -- having the concept of "dog" to begin with and then training the neural nets with it -- is still being done by actual brains.
That's not to say that, eventually, we won't have far more complex neural nets that generate "hallucinogenic" images of melting dogs that are actually at those deeper levels quite like what our brains produce; however, these images aren't really that. But they are very similar otherwise.
posted by Ivan Fyodorovich at 11:19 AM on June 18, 2015 [2 favorites]
I don't see any electric sheep.
That's because it's not available on Android yet.
posted by Greg_Ace at 11:24 AM on June 18, 2015 [14 favorites]
That's because it's not available on Android yet.
posted by Greg_Ace at 11:24 AM on June 18, 2015 [14 favorites]
odinsdream, yeah, imagine the local police training the face hallucinator on their database of mugshots, which for some reason may not proportionally represent the local population; and then see who its hallucinations look like.
posted by moonmilk at 11:45 AM on June 18, 2015 [3 favorites]
posted by moonmilk at 11:45 AM on June 18, 2015 [3 favorites]
I'm a little worried that the goddamn melting squirrel image might turn out to be an accidentally-created Langford Basilisk, and that now that I've seen it, I'm going to be dead within 48 hours from the Godelian shock input.
posted by webmutant at 12:03 PM on June 18, 2015 [7 favorites]
posted by webmutant at 12:03 PM on June 18, 2015 [7 favorites]
We taught the AI to create tryptophobia triggers. Thanks, science!
posted by jjwiseman at 12:06 PM on June 18, 2015 [1 favorite]
posted by jjwiseman at 12:06 PM on June 18, 2015 [1 favorite]
So yeah - saw the otter thingy one a few days ago and was like HOLY FUCKING SHIT. YOU GUYS YOU GUYS!!!! And had to show my roommates and be like "THIS IS IT!" And the fact that everyone else who's tripped totally gets it means that there's definitely a connection there of some sort.
Speaking of training it, yeah, I was thinking of that in the sort of Platonic sense of "here are these ideal forms - now see them in the perlin shadow" and how that's great for some kantian sense of philosophy, but what I want is generation. Not of pre-existing images/models but of NEW things. In the same way we create things out of disparate parts.
In some sense, you could say that it is doing that (adding an owlhead to a fish body in some Boschian nightmare trip), but I mean to be more original, not just gluing random pictures (granted when you look at a lot of art produced under tripping, this is sorta what happens... you sorta just ... swirl and go with the pen and then let it build itself out of the lines as your mind connects the dots, spins the web, whatever you want to call it).
But how cool would it be to add a semantic core to this recognition / generation system. "A wheel does this" "people want to go places" "A car has people inside". What happens when this network learns to piece together things by purpose. Terence McKenna's head would trip on this.
posted by symbioid at 12:25 PM on June 18, 2015
Speaking of training it, yeah, I was thinking of that in the sort of Platonic sense of "here are these ideal forms - now see them in the perlin shadow" and how that's great for some kantian sense of philosophy, but what I want is generation. Not of pre-existing images/models but of NEW things. In the same way we create things out of disparate parts.
In some sense, you could say that it is doing that (adding an owlhead to a fish body in some Boschian nightmare trip), but I mean to be more original, not just gluing random pictures (granted when you look at a lot of art produced under tripping, this is sorta what happens... you sorta just ... swirl and go with the pen and then let it build itself out of the lines as your mind connects the dots, spins the web, whatever you want to call it).
But how cool would it be to add a semantic core to this recognition / generation system. "A wheel does this" "people want to go places" "A car has people inside". What happens when this network learns to piece together things by purpose. Terence McKenna's head would trip on this.
posted by symbioid at 12:25 PM on June 18, 2015
I am so ready to upload. Where do I volunteer? Pick me, pick me, take me with you!
posted by Meatbomb at 12:25 PM on June 18, 2015
posted by Meatbomb at 12:25 PM on June 18, 2015
Is anybody else getting a migraine-aura vibe from these?
posted by mikurski at 12:39 PM on June 18, 2015 [3 favorites]
posted by mikurski at 12:39 PM on June 18, 2015 [3 favorites]
Unrelatedly, this quote from the Medium article is pretty hilarious:
posted by invitapriore at 12:46 PM on June 18, 2015
“It’s not perfect, the same way that voice transcription five years ago was not perfect,” vice president of Streams, Photos, and Sharing Bradley Horowitz says.The fact that anybody at Google would be willing to imply that commodity voice transcription has gotten over the hurdle of being "not perfect" really explains a lot about their software.
posted by invitapriore at 12:46 PM on June 18, 2015
Anyway, so as someone who did machine learning work with much simpler NNs in a feature space with many fewer dimensions, a question I have about deep networks in light of the fact that even NNs with a single hidden layer are universal approximators is: do the different levels of abstraction learned by successive layers of the network just sort of emerge out of the same type of back-propagation training you'd do on a single layer network, or are they explicitly targeted (e.g. I'm imagining maybe doing a training pass with different training sets that train for edge detection, then maybe circles, then eyes, or something, I don't know, I'm making this up entirely)?
posted by invitapriore at 12:53 PM on June 18, 2015
posted by invitapriore at 12:53 PM on June 18, 2015
Some of this stuff is beautiful. The neon renderings of fractal archways? Gorgeous. The times when it sees dogs in everything, not so much.
I kind of want to try feeding this some of my art. Which is super-simplified and evocative; I essentially depend on the human brain running similar processes to fill in the gaps. I'm sure the size of the database required for this process will make turning it into a Photoshop plugin prohibitive for some years to come.
I'm also curious as to whether this involves any randomness. I want to feed it successive images of, say, one patch of a cloudy sky, or a bubbling stream. Or of a kaleidoscopic screensaver, for that matter. Would it generate a wildly different image from each frame? Or would things slowly evolve and change in time with the original video clip? Could it be tweaked to do that?
Aaaand the overall process (take random image, say 'that kinda looks like this thing', make it look more like that thing, repeat) is one I've used myself. I have piles of sketchbooks full of weird drawings I did when I was stoned by starting with some random lines, or a half-assed sketch of something on the TV screen, and following that method of a while.
I have a lot of projects to do. Lots of art to generate by myself. But damn. I want to take this and play with it. Play with giving it different input sets, hand-made input, and so on.
posted by egypturnash at 1:31 PM on June 18, 2015 [1 favorite]
I kind of want to try feeding this some of my art. Which is super-simplified and evocative; I essentially depend on the human brain running similar processes to fill in the gaps. I'm sure the size of the database required for this process will make turning it into a Photoshop plugin prohibitive for some years to come.
I'm also curious as to whether this involves any randomness. I want to feed it successive images of, say, one patch of a cloudy sky, or a bubbling stream. Or of a kaleidoscopic screensaver, for that matter. Would it generate a wildly different image from each frame? Or would things slowly evolve and change in time with the original video clip? Could it be tweaked to do that?
Aaaand the overall process (take random image, say 'that kinda looks like this thing', make it look more like that thing, repeat) is one I've used myself. I have piles of sketchbooks full of weird drawings I did when I was stoned by starting with some random lines, or a half-assed sketch of something on the TV screen, and following that method of a while.
I have a lot of projects to do. Lots of art to generate by myself. But damn. I want to take this and play with it. Play with giving it different input sets, hand-made input, and so on.
posted by egypturnash at 1:31 PM on June 18, 2015 [1 favorite]
> I kind of want to try feeding this some of my art.
I'll bet a dollar this will be available in a Photoshop plugin within 2 years.
posted by doctor tough love at 2:01 PM on June 18, 2015 [1 favorite]
I'll bet a dollar this will be available in a Photoshop plugin within 2 years.
posted by doctor tough love at 2:01 PM on June 18, 2015 [1 favorite]
The half-mutated creatures are also straight out of the mind of cyriak.
posted by scruss at 2:02 PM on June 18, 2015 [5 favorites]
posted by scruss at 2:02 PM on June 18, 2015 [5 favorites]
I get the impression that they have more than one kind of neural net for this kind of purpose, and they get the image results by letting select layers of the nets "enhance" the image. That's why they can get different results from the same image.
posted by surazal at 2:14 PM on June 18, 2015
posted by surazal at 2:14 PM on June 18, 2015
Does anyone know whether there are videos / gifs of the interations anywhere?
Here's a video of.... something:
https://photos.google.com/share/AF1QipPX0SCl7OzWilt9LnuQliattX4OUCj_8EP65_cTVnBmS1jnYgsGQAieQUc1VQWdgQ/photo/AF1QipOlM1yfMIV0guS4bV9OHIvPmdZcCngCUqpMiS9U?key=aVBxWjhwSzg2RjJWLWRuVFBBZEN1d205bUdEMnhB
posted by jjwiseman at 3:01 PM on June 18, 2015 [8 favorites]
Here's a video of.... something:
https://photos.google.com/share/AF1QipPX0SCl7OzWilt9LnuQliattX4OUCj_8EP65_cTVnBmS1jnYgsGQAieQUc1VQWdgQ/photo/AF1QipOlM1yfMIV0guS4bV9OHIvPmdZcCngCUqpMiS9U?key=aVBxWjhwSzg2RjJWLWRuVFBBZEN1d205bUdEMnhB
posted by jjwiseman at 3:01 PM on June 18, 2015 [8 favorites]
Here's a video of.... something:
Quadcopter with a GoPro enters heaven
posted by moonmilk at 3:10 PM on June 18, 2015 [2 favorites]
Quadcopter with a GoPro enters heaven
posted by moonmilk at 3:10 PM on June 18, 2015 [2 favorites]
Some of that stuff is scary impressive, like really reminiscent of ways human visual systems process stuff. I mean, obviously, animals from clouds! Giving machines pareidolia might raise some troubling philosophical stuff about how special art really is. Also, give me real-time this in a VR headset.
posted by Nomiconic at 4:13 PM on June 18, 2015 [3 favorites]
posted by Nomiconic at 4:13 PM on June 18, 2015 [3 favorites]
Giving machines pareidolia might raise some troubling philosophical stuff about how special art really is.
These ideas about the specialness of art really hold us back. They should go away. Art is what happens when people creatively make sense of stuff that's not working.
Consciousness is another thing we should really de-mystify. And self-awareness.
The more we stay hung up on the things that make humans human, the less we are able to understand what really makes humans work. It's our commonalities with other animals that are going to tell us that, not our differences from them.
posted by lodurr at 5:57 PM on June 18, 2015 [3 favorites]
These ideas about the specialness of art really hold us back. They should go away. Art is what happens when people creatively make sense of stuff that's not working.
Consciousness is another thing we should really de-mystify. And self-awareness.
The more we stay hung up on the things that make humans human, the less we are able to understand what really makes humans work. It's our commonalities with other animals that are going to tell us that, not our differences from them.
posted by lodurr at 5:57 PM on June 18, 2015 [3 favorites]
So what would come out if you plugged a Hieronymus Bosch into this? An apple on a table? A guy sitting at a desk? A brick?
posted by sexyrobot at 7:31 PM on June 18, 2015 [4 favorites]
posted by sexyrobot at 7:31 PM on June 18, 2015 [4 favorites]
Anyway, so as someone who did machine learning work with much simpler NNs in a feature space with many fewer dimensions, a question I have about deep networks in light of the fact that even NNs with a single hidden layer are universal approximators is: do the different levels of abstraction learned by successive layers of the network just sort of emerge out of the same type of back-propagation training you'd do on a single layer network, or are they explicitly targeted (e.g. I'm imagining maybe doing a training pass with different training sets that train for edge detection, then maybe circles, then eyes, or something, I don't know, I'm making this up entirely)?
No, they don't need separate training sets. The elementary feature-detectors emerge because they're so useful.
posted by a snickering nuthatch at 9:41 PM on June 18, 2015 [1 favorite]
No, they don't need separate training sets. The elementary feature-detectors emerge because they're so useful.
posted by a snickering nuthatch at 9:41 PM on June 18, 2015 [1 favorite]
Here's a video of.... something:
The opening seconds of that - as we go from a photo into a world created from its interpretation - are stunning. It conveys that whole kind of Lion the Witch and the Wardrobe portal feel - but the other world that we fly into is based wholly on a visual examination of this one.
posted by rongorongo at 3:38 AM on June 19, 2015
The opening seconds of that - as we go from a photo into a world created from its interpretation - are stunning. It conveys that whole kind of Lion the Witch and the Wardrobe portal feel - but the other world that we fly into is based wholly on a visual examination of this one.
posted by rongorongo at 3:38 AM on June 19, 2015
The elementary feature-detectors emerge because they're so useful.
That's kind of amazing in itself.
posted by moonmilk at 6:32 AM on June 19, 2015
That's kind of amazing in itself.
posted by moonmilk at 6:32 AM on June 19, 2015
On the one hand these are astonishingly beautiful, and I want giant versions on my walls. On the other hand, they seem to be radiating evil and breaking my brain a little. But I still want them on my wall, which is probably part of their evil plan.
Seriously, stare at this for a while.
posted by diogenes at 10:27 AM on June 19, 2015 [2 favorites]
Seriously, stare at this for a while.
posted by diogenes at 10:27 AM on June 19, 2015 [2 favorites]
Here's a video of.... something:
Aaargh. I mean, that's extremely interesting, but also Aaargh. The only reason I've never tried hallucinogens is that I'm terrified I'd be stuck experiencing something like that for hours on end.
posted by metaBugs at 11:23 AM on June 19, 2015
Aaargh. I mean, that's extremely interesting, but also Aaargh. The only reason I've never tried hallucinogens is that I'm terrified I'd be stuck experiencing something like that for hours on end.
posted by metaBugs at 11:23 AM on June 19, 2015
Yeah, that was pretty strikingly similar to my experience with hallucinogens.
posted by latkes at 12:25 PM on June 19, 2015
posted by latkes at 12:25 PM on June 19, 2015
sexyrobot: So what would come out if you plugged a Hieronymus Bosch into this? An apple on a table? A guy sitting at a desk? A brick?
well let's think about it. I have a suspicion that you would actually make it worse. 'How?' you might well ask. Consider that Bosch is often using parts of bodies and torturing them visually. What are the algorithms going to find in those? My money is on more melted humans than apples on tables.
posted by lodurr at 12:37 PM on June 19, 2015
well let's think about it. I have a suspicion that you would actually make it worse. 'How?' you might well ask. Consider that Bosch is often using parts of bodies and torturing them visually. What are the algorithms going to find in those? My money is on more melted humans than apples on tables.
{kind=link}
posted by lodurr at 12:37 PM on June 19, 2015
Don't do it, man. It would be like crossing the streams.
posted by Johnny Wallflower at 2:32 PM on June 19, 2015 [2 favorites]
posted by Johnny Wallflower at 2:32 PM on June 19, 2015 [2 favorites]
Facebook's New AI Can Paint, But Google's Knows How To Party
posted by the man of twists and turns at 9:31 AM on June 22, 2015
posted by the man of twists and turns at 9:31 AM on June 22, 2015
Artificially Flavored Intelligence
posted by the man of twists and turns at 8:21 AM on June 23, 2015 [1 favorite]
posted by the man of twists and turns at 8:21 AM on June 23, 2015 [1 favorite]
Some grad students in Belgium, inspired by google, made a live video stream of a neural network which takes viewers' suggestions of what to hallucinate.
posted by moonmilk at 8:38 PM on June 24, 2015 [2 favorites]
posted by moonmilk at 8:38 PM on June 24, 2015 [2 favorites]
Google has released sample code to accompany the blog post: https://github.com/google/deepdream
posted by jjwiseman at 7:14 PM on July 1, 2015 [1 favorite]
posted by jjwiseman at 7:14 PM on July 1, 2015 [1 favorite]
Here's a pretty good album of images generated with the Google code.
posted by jjwiseman at 6:53 AM on July 2, 2015
posted by jjwiseman at 6:53 AM on July 2, 2015
Zain Shah has used the released code to make a tool to hallucinatify your own photos, though it seems pretty overloaded at the moment: http://deepdreams.zainshah.net/
I made this dog dream with it.
posted by moonmilk at 8:43 AM on July 2, 2015 [1 favorite]
I made this dog dream with it.
posted by moonmilk at 8:43 AM on July 2, 2015 [1 favorite]
Another album, including a Hieronymous Bosch.
posted by jjwiseman at 9:03 AM on July 2, 2015 [1 favorite]
posted by jjwiseman at 9:03 AM on July 2, 2015 [1 favorite]
yup, pretty much what I expected. Not quite as bad, but close.
posted by lodurr at 9:05 AM on July 2, 2015
posted by lodurr at 9:05 AM on July 2, 2015
Holy crap, I didn't think Bosch could get any creepier.
posted by Johnny Wallflower at 9:59 AM on July 2, 2015
posted by Johnny Wallflower at 9:59 AM on July 2, 2015
Not exactly crossing the streams, but definitely creepier.
posted by lodurr at 11:01 AM on July 2, 2015
posted by lodurr at 11:01 AM on July 2, 2015
{kind=link}
Also, if you want to install Caffe on OS X, this guide is mostly correct. The one difference is (assuming you've installed Python via Homebrew, which is the only way I've gotten it to work -- neither the Anaconda distribution nor the system Python seem to function correctly when you import the pycaffe module) that you should set the
The
This all assumes that you've already installed pycaffe's dependencies via pip, which you can do by cding to $CAFFE_DIR/python/caffe and running
That install guide recommends setting the
posted by invitapriore at 9:49 PM on July 3, 2015 [2 favorites]
PYTHON_INCLUDE variable in Makefile.config to something like the following, so that the pycaffe module gets compiled consistently and only against the Homebrew Python includes and shared libs:PYTHON_INCLUDE := /usr/local/Cellar/python/2.7.10/Frameworks/Python.framework/Versions/2.7/include/python2.7 \
/usr/local/Cellar/python/2.7.10/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/numpy/core/includeThe
PYTHON_LIB variable is set correctly in the example Makefile.config shown there, except that Python 2.7.10 has been released in the meantime, so if you copy and paste that you'll want to make sure to adjust the version numbers appropriately if you've only just recently installed Python via Homebrew.This all assumes that you've already installed pycaffe's dependencies via pip, which you can do by cding to $CAFFE_DIR/python/caffe and running
pip install -r requirements.txt. (I have no idea why nobody involved in creating this software seems to know that you don't need to iterate over the lines of requirements.txt in bash and run pip independently for each one.)That install guide recommends setting the
CPU_ONLY flag, which I did in my case since I don't have an nVidia GPU, but I imagine it would work just fine if you do have one and want to enable GPU-based computation, and I imagine that will speed up the proceedings quite a bit. Unfortunately, I think that the compile process requires the CUDA shared libs either way, so I believe you have to install CUDA no matter what.posted by invitapriore at 9:49 PM on July 3, 2015 [2 favorites]
And actually the notion of gradient ascent to maximize the L2 norm of the activations of an NN layer is pretty well within grasp, really the only prior knowledge necessary is what a vector is, and what a derivative is.
Let's take as example this image. We'll focus on the middle layer with four "neurons" there. The arrows from the left-most layer represent the outputs of those three neurons; as you can see, each neuron in the second layer gets input from all of the neurons in the previous one. Each arrow has a coefficient called a "weight" associated with it. To find the output from one of our four example neurons, let's call it A, we just compute this value:
F(wA1 * o1 + wA2 * o2 + wA3 * o3)
Where F is some function with useful properties, wA1 is the weight on the arrow going from the first neuron in the left-most layer to neuron A in the middle layer, and o1 is the output from the first neuron in the left-most layer. That value is neuron A's "activation."
Now, if we've got all of the activations for a given layer, we can assemble them into a vector [aA, aB, aC, aD], where aA is neuron A's activation, and so on. The L2 norm in this case is equivalent to what we would get if we just treated that vector as a point in 4D space and wanted to find its distance to the origin:
sqrt(aA^2 + aB^2 + aC^2 + aD^2)
So the last ingredient here is gradient ascent. Remember that, even though it looks like the equation above only has four inputs (the four activations from the middle layer), each of those activations depends itself on the weights of the three arrows that point to its neuron. So what we want to do is find values for all of the weights from the left-most layer to the middle layer that result in the maximum possible value for the L2 norm shown above (since this is done on a layer-by-layer basis, we assume that the activations from the left-most layer are fixed and can't be adjusted). In this case, that's twelve different values (one for each arrow between the left-most layer and the middle layer), so maybe we could find the maximum value of that L2 norm function on paper by some algebraic manipulations (this is called an analytic solution). But in practice we frequently encounter situations where we can't find the maximum that way, either because there are just too many weights or because there is no sequence of mathematical steps we can take to get to it from the equation we have. What we usually can do, though, is compute the gradient at any given point for that function. The gradient at a point is a vector of the partial derivatives with respect to every dimension of the space, and it points in the direction where the "slope" of the function is steepest. We have twelve weights, and so we have twelve dimensions. To perform gradient ascent, we choose some random point in this twelve dimensional space, find the gradient, and move a little bit in that direction. You can imagine how going a little bit in the steepest direction will guarantee that you always move up, and moreover that you do so as quickly as possible. Then we find the gradient at this new point, and move a little bit in that direction again, and we keep doing this until we find that we can't get any higher. We've found our maximum! It may not be the global maximum of the function, but it'll do.
If you assume that the activations represent a response to seeing a certain feature, and that each layer is looking for its own type of feature, then it maybe becomes a little clearer as to why maximizing the L2 norm of a given layer causes the hallucinations: basically, the image is adjusted until that particular layer says "yes! I see SO MANY DOGS!!"
One big caveat to my explanation is that the process involved in creating these images doesn't actually adjust the weights, it adjusts the input image itself. I don't actually know the details of how this works (I kind of want to read the papers they cite that describe this process), but the above explanation of just what that sentence means still holds, pretty much.
posted by invitapriore at 12:22 AM on July 4, 2015 [4 favorites]
Let's take as example this image. We'll focus on the middle layer with four "neurons" there. The arrows from the left-most layer represent the outputs of those three neurons; as you can see, each neuron in the second layer gets input from all of the neurons in the previous one. Each arrow has a coefficient called a "weight" associated with it. To find the output from one of our four example neurons, let's call it A, we just compute this value:
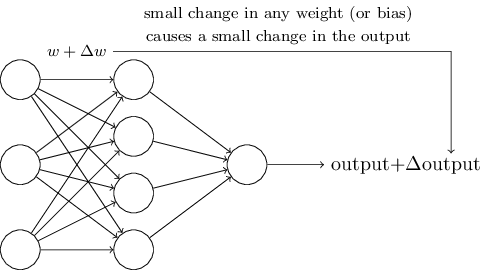{kind=link}
F(wA1 * o1 + wA2 * o2 + wA3 * o3)
Where F is some function with useful properties, wA1 is the weight on the arrow going from the first neuron in the left-most layer to neuron A in the middle layer, and o1 is the output from the first neuron in the left-most layer. That value is neuron A's "activation."
Now, if we've got all of the activations for a given layer, we can assemble them into a vector [aA, aB, aC, aD], where aA is neuron A's activation, and so on. The L2 norm in this case is equivalent to what we would get if we just treated that vector as a point in 4D space and wanted to find its distance to the origin:
sqrt(aA^2 + aB^2 + aC^2 + aD^2)
So the last ingredient here is gradient ascent. Remember that, even though it looks like the equation above only has four inputs (the four activations from the middle layer), each of those activations depends itself on the weights of the three arrows that point to its neuron. So what we want to do is find values for all of the weights from the left-most layer to the middle layer that result in the maximum possible value for the L2 norm shown above (since this is done on a layer-by-layer basis, we assume that the activations from the left-most layer are fixed and can't be adjusted). In this case, that's twelve different values (one for each arrow between the left-most layer and the middle layer), so maybe we could find the maximum value of that L2 norm function on paper by some algebraic manipulations (this is called an analytic solution). But in practice we frequently encounter situations where we can't find the maximum that way, either because there are just too many weights or because there is no sequence of mathematical steps we can take to get to it from the equation we have. What we usually can do, though, is compute the gradient at any given point for that function. The gradient at a point is a vector of the partial derivatives with respect to every dimension of the space, and it points in the direction where the "slope" of the function is steepest. We have twelve weights, and so we have twelve dimensions. To perform gradient ascent, we choose some random point in this twelve dimensional space, find the gradient, and move a little bit in that direction. You can imagine how going a little bit in the steepest direction will guarantee that you always move up, and moreover that you do so as quickly as possible. Then we find the gradient at this new point, and move a little bit in that direction again, and we keep doing this until we find that we can't get any higher. We've found our maximum! It may not be the global maximum of the function, but it'll do.
If you assume that the activations represent a response to seeing a certain feature, and that each layer is looking for its own type of feature, then it maybe becomes a little clearer as to why maximizing the L2 norm of a given layer causes the hallucinations: basically, the image is adjusted until that particular layer says "yes! I see SO MANY DOGS!!"
One big caveat to my explanation is that the process involved in creating these images doesn't actually adjust the weights, it adjusts the input image itself. I don't actually know the details of how this works (I kind of want to read the papers they cite that describe this process), but the above explanation of just what that sentence means still holds, pretty much.
posted by invitapriore at 12:22 AM on July 4, 2015 [4 favorites]
And now someone has dockerized the Google code, do you don't have to go through the pretty unwieldy process of installing cafe and the CUDA libraries and etc.: https://github.com/VISIONAI/clouddream
posted by jjwiseman at 1:29 PM on July 6, 2015 [3 favorites]
posted by jjwiseman at 1:29 PM on July 6, 2015 [3 favorites]
There's lots of packaging up of the deepdream code now. The dockerized appliance I linked to above makes it easy to process images and videos, while DeepDream animator helps create animations: https://github.com/samim23/DeepDreamAnim
posted by jjwiseman at 8:28 AM on July 7, 2015 [1 favorite]
posted by jjwiseman at 8:28 AM on July 7, 2015 [1 favorite]
« Older The Nightwalker and the Nocturnal Picaresque | Does there happen to be a historically interesting... Newer »
This thread has been archived and is closed to new comments
posted by Johnny Wallflower at 10:58 PM on June 17, 2015 [10 favorites]